* 본인 파트는 서버리스 아키텍처, 웹 프론트/백엔드 담당이기에 유니티 파트는 자세히 다루지 않겠음
유니티 파트의 간단한 개요

인프라 설계
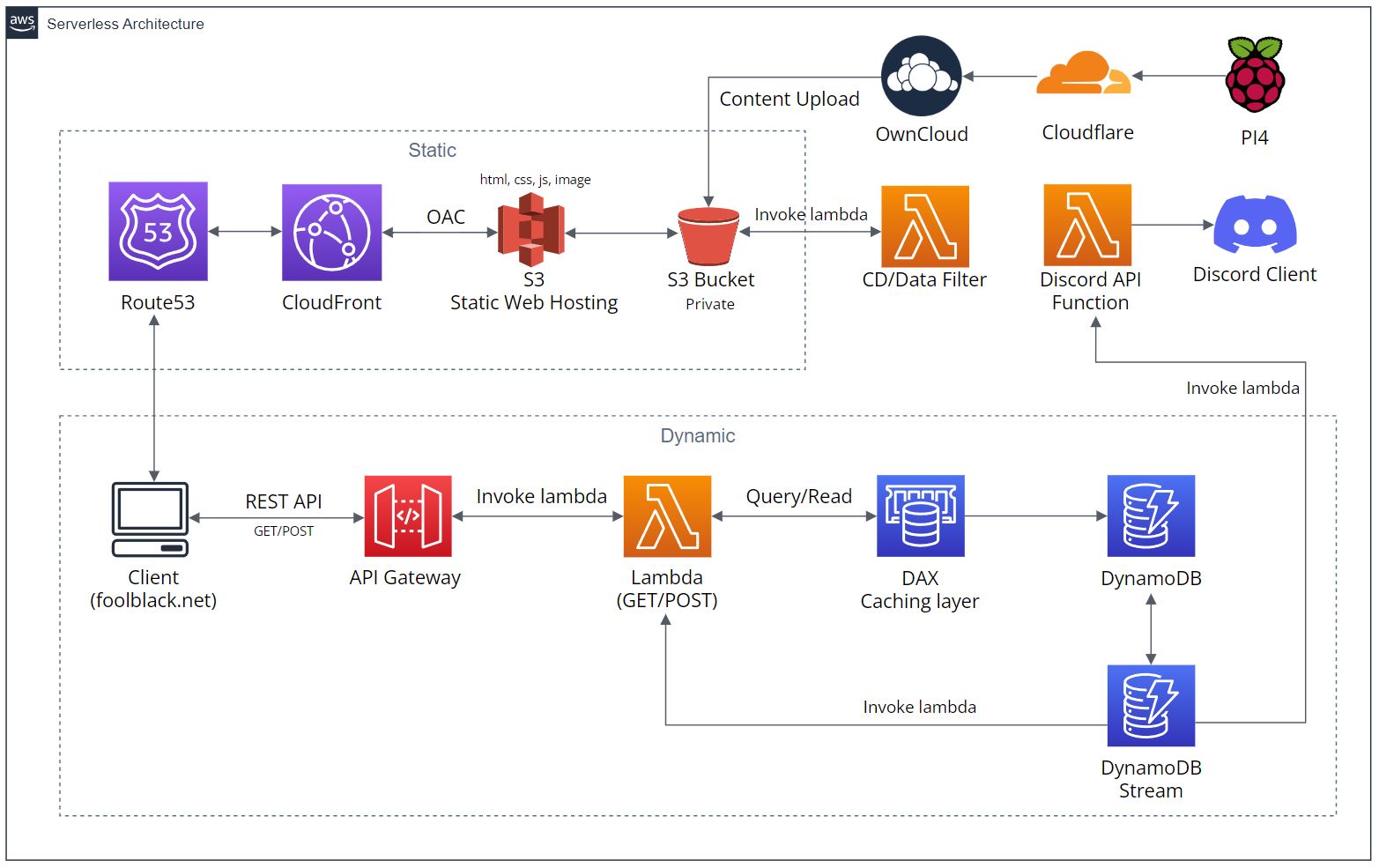
게임 엔진과, 그 외 미디어 데이터 파일들의 리소스 용량이 꽤나 크기 때문에 캐싱 솔루션이 무조건 필요하다고 생각했다.
기존에 가지고 있었던 웹 호스팅을 통해 테스트를 하는 도중 웹 트래픽 용량 크기가 1500M인데 여러 번 사이트를 로드하지 않았는데도 모든 트래픽 용량을 다 사용해 버렸다.
결론적으로 사용자들을 위해 효율적인 운영과 개발과 배포 작업에 있어서 편의성을 추구하려면 웹 호스팅만으로는 굉장히 제한적이기 때문에 위 아키텍처를 구성한 것이다.
왜 서버리스냐?
사실 이 부분이 가장 크기도 했는데 많은 사람들이 학교 프로젝트를 진행하면서 기술 스택에 넣기 위해 AWS를 많이 사용하고 간단하게 인스턴스를 프로비저닝 하여 앱을 많이 굴린다.
여기서 인프라를 좀 더 신경 써서 가용성과 확장성, 보안을 생각하여 ASG(다양한 조정 정책), 액세스 분류에 따른 VPC(퍼블릭, 프라이빗), RDS Multi-AZ.. 등등 많은 솔루션들을 적용할 수 있지만 사실 이런 부분에 있어서 비용적인 부분이 가장 걱정되는 부분이다.
그래서 프로젝트 발표 및 시연이 끝나면 추가적인 비용이 발생하는 걸 막기 위해 기존에 구축했던 인프라를 지운다.
즉 서버리스 아키텍처의 특징인 유휴시간 동안 비용이 발생하지 않고 특정 이벤트에 관련해서만 동작하기 때문에 비용적인 부담을 대폭 줄일 수 있다는 점이 가장 큰 장점이다.
단점이라고 할 것은 이벤트 기반으로 동작하기 때문에 다양한 서비스와의 연동이 많아질수록 아키텍처가 복잡해질 수 있다. 즉 크기가 커질수록 잘못 설계할 경우 유지보수와 확장이 어려울 수 있다.
또한 개발 기술 스택의 폭이 그렇게 크지는 않다.
Lambda 같은 경우 JavaScript, Python, Java, C#, Ruby 등을 지원하지만, 모든 언어나 프레임워크를 지원하지는 않는다.
(베이스도 제대로 잡히지 않았던 Python을 활용해서 개발하는데 조금 애를 많이 먹었다.)
Dynamic 파트
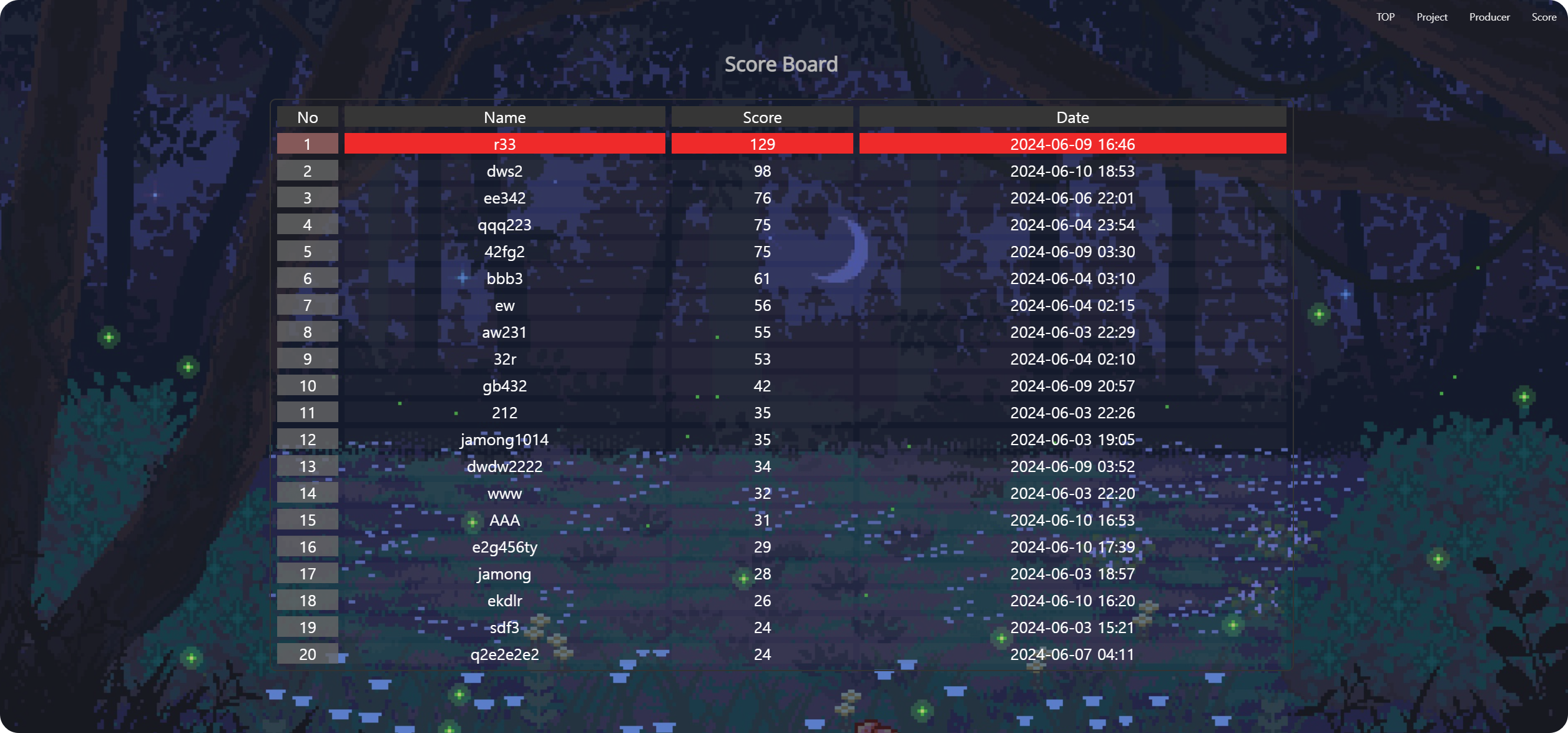
먼저 NoSQL인 DynamoDB를 사용했고 Stream 기능을 활성화하여 안에서 발생하는 CRUD에 대한 모든 이벤트를 트리거하여 Lambda 함수를 호출할 수 있다.
클라이언트(유니티) 측에서 데이터를 전송하면 REST API 기반인 API Gateway URL을 통해 POST(Lambda) 형식으로 넣어주고, 값이 들어가게 되면 GET(Lambda)가 호출되어 데이터를 반환해 주어 웹 사이트에서 사용자들의 게임 기록을 보여주는 형식이다.
여기서 Stream 기능을 통해 트리거할 수 있는 것이 한 가지 더 있는데 디스코드 봇을 호출하는 것이다.

프로젝트를 진행하면서 솔루션 담당이 아닌 유니티 개발자 또한 DB에 접근하여 데이터가 정상적으로 들어가는 것을 확인해야 한다.
솔루션 담당자는 제한된 권한을 할당하여 IAM 계정을 따로 제공해 줄 수도 있지만 보안적인 부분과, 커뮤니케이션을 생각하여 DB에 대한 이벤트를 트리거하여 람다 함수를 호출해서 디스코드 봇을 동작시키도록 구현했다.
Static 파트
먼저 정적인 데이터들은 모두 Cloudfront를 통해 캐싱 히트가 이루어져야 한다.
그래야 보다 빠르고 효율적인 사이트 운영이 가능하다.
S3 버킷의 웹 호스팅 기능을 활성화하여 HTML, CSS, JS, IMG 등을 호스팅 해주는 엔드포인트 URL을 제공받는다.
여기서 버킷을 퍼블릭으로 설정해 버리면 보안에 취약하기 때문에 프라이빗으로 설정하고 따로 Cloudfront로 배포한 도메인으로만 접속할 수 있는 OAC를 설정해줘야 한다.
그리고 한번 캐싱 히트가 되어버리면 그 이후에 바뀌는 데이터에 있어서는 Invalidations(무효화) 작업을 해줘야 한다.
파일 공유는 기존에 가지고 있었던 서버 OwnCloud를 통해 제공했으며 S3 버킷과 연동하여 유니티 개발자가 작업 후 웹 엔진으로 빌드 후에 리소스들을 업로드한다.
업로드하게 되면 S3 버킷에서 이벤트를 트리거하여 Lambda 함수를 호출.
웹 사이트 구조에 맞게 데이터 필터링 작업/무효화 작업이 자동화로 이루어지고 배포가 이루어지는 것이다.



개선해야 할 점
조금 더 비용 효율적인 부분에 있어서 Cloudfront가 아닌 도메인 자체도 Cloudflare 리버스 프록시 솔루션을 적용시키는 것.
Cloudflare는 단순 캐싱 솔루션뿐만이 아닌 다양한 솔루션들도 통합이 가능하기에 다음 프로젝트 때 적용해 볼 예정이다.
그리고 Cloudfront 특정 오브젝트 호출 시 문제점이다.
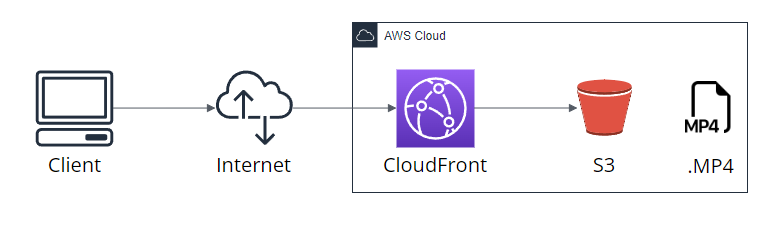
현재는 이런 식으로 구성되어서 특정 .mp4 같은 특정 오브젝트들이 캐싱 미스가 뜨는 경우가 발생한다.
그럼 불필요한 리소스를 계속 낭비하게 된다.
이런 문제를 해결하고자 밑에처럼 구성할 수 있다.
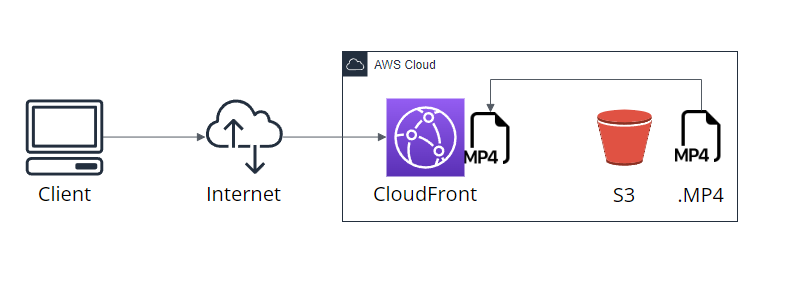
이렇게 구성하면 S3까지 트래픽이 이동하지 않기 때문에 비용 효율적으로 운영할 수 있고 S3 버킷에 업로드될 때마다 Cloudfront에 적재시킬 수 있기 때문에 처음 페이지를 로드할 때도 캐싱 히트로 로드시킬 수 있다.
대신 Cloudfront는 TTL 기준으로 데이터를 업데이트하기 때문에 Invalidations(무효화)를 통해 수동으로 캐싱 삭제를 해야 하지만 이 작업 또한 Lambda 함수를 호출하여 자동화시킬 수 있기 때문에 훨씬 효율적이다.
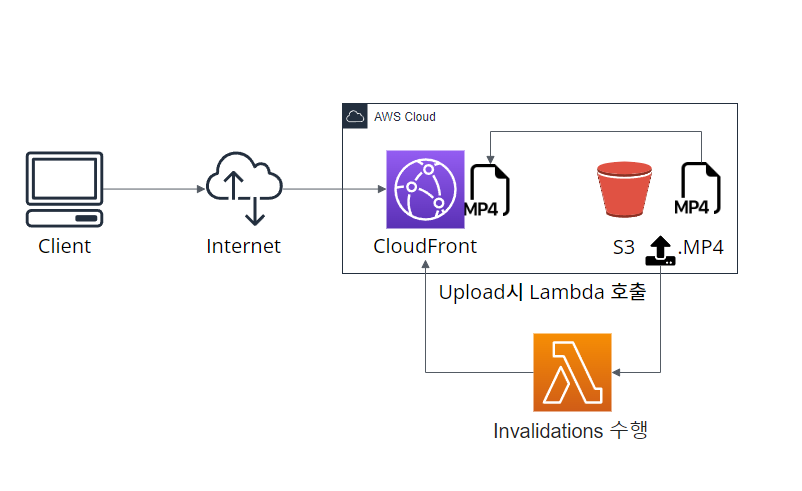
이런 식의 인프라가 구성될 것이다.
소감
이번 프로젝트를 진행하면서 어떻게 하면 더 편하게 작업할 수 있고 더 효율적으로 배포할 수 있을까에 대한 생각을 많이 할 수 있었다.
프로젝트를 다 만들고 나서도 더 효율적으로 구성할 수 있는 방법이 굉장히 많이 존재했었고 확실히 프로젝트를 진행해야 여러 가지 상황에 맞게 이런저런 솔루션을 통합해서 사용해 볼 수 있는 경험이 생기는 것 같다.
다음 프로젝트를 진행할 땐 좀 더 효율적인 서버리스를 구축하고, 따로 인스턴스를 프로비저닝 하여 세부적인 관리를 할 수 있는 인프라 또한 적용해 보는 시간을 가져보겠다.
'포트폴리오 > 개인 자작' 카테고리의 다른 글
| [2인 프로젝트] 웹과 유니티를 결합한 방탈출 게임 개발 및 배포 (2) | 2024.12.07 |
|---|---|
| [토이 프로젝트] 클라이밍 스스로 규칙 앱 개발 Feat. S3 presigned_url (1) | 2024.07.14 |
| 철권8 자동 스코어 봇 개발 (Feat. AWS) (4) | 2024.04.02 |
| 긴급 구조 SOS 시스템 개발 프로젝트 (4) | 2023.12.01 |
| [2022] Hackathon AI 졸음 운전 검문소 (0) | 2023.12.01 |



