Use GPUs on Azure Kubernetes Service (AKS) - Azure Kubernetes Service
Learn how to use GPUs for high performance compute or graphics-intensive workloads on Azure Kubernetes Service (AKS).
learn.microsoft.com
시나리오
- 대규모 AI/ML 트레이닝
- CPU 노드 풀 + GPU 노드 풀 2개로 구성 (Join)
- CPU 노드 풀은 모니터링/로그 수집 및 일반 API 서버 용도
- GPU 노드의 여러 파드로 병렬 처리
- AKS GPU 노드 풀 구성 시 고려해야 할 이슈
1. GPU 노드풀 구성
NVIDIA GPU 드라이버 & CUDA 라이브러리
- GPU VM SKU에는 기본적으로 NVIDIA 드라이버가 설치되어 있음.
- 하지만 쿠버네티스는 기본적으로 GPU를 리소스 타입으로 인식하지 않으므로 NVIDIA Device Plugin을 추가 설치해야 함.
- Device Plugin은 노드의 GPU를 탐지해 kubelet에 nvidia.com/gpu 리소스로 등록
CUDA 환경
- GPU 연산을 위한 NVIDIA의 프로그래밍 플랫폼.
- NVIDIA가 Docker Hub에 올려둔 컨테이너 이미지 사용 가능 (예 : nvidia/cuda:12.2.0-base-ubuntu22.04)
- 컨테이너 내에서 nvidia-smi 실행 가능 → GPU 상태 확인.
2. GPU 모니터링 (DCGM Exporter)
Azure Monitor는 GPU 메트릭을 기본 제공하지 않음.
따라서 NVIDIA의 DCGM Exporter를 사용해야 한다.
- 모든 GPU 노드에 DaemonSet으로 배포
- GPU 사용률, 메모리 사용량 등 지표 수집
- Prometheus 형식으로 내보내기 → Managed Prometheus/Grafana와 연동
배포 절차
- DCGM Exporter 이미지를 ACR(Azure Container Registry)에 Push (프라이빗 엔드포인트 지원)
- Helm 차트로 배포
- Prometheus/Grafana와 통합
3. GPU 워크로드 스케줄링
GPU 노드 전용으로 파드를 배포할 때는 nodeSelector, tolerations, taints 설정을 활용
- nodeSelector : Pod가 특정 라벨이 붙은 노드에게만 실행되도록 강제.
- taints : 노드에 '이 파드는 못 올라와'라고 명시 즉 tolerations이 설정된 pod만 올라올 수 있음.
- tolerations : Pod가 특정 Taint를 허용한다고 선언
apiVersion: v1
kind: Pod
metadata:
name: gpu-test
spec:
nodeSelector:
pool: gpu # GPU 노드풀 라벨
tolerations:
- key: "sku"
operator: "Equal"
value: "gpu"
effect: "NoSchedule"
containers:
- name: cuda
image: nvidia/cuda:12.2.0-base-ubuntu22.04
command: [ "sleep", "3600" ]
resources:
limits:
nvidia.com/gpu: 1 # GPU 1개 요청
* 또한, DCGM 메트릭 + KEDA(외부 이벤트/메트릭 기반 스케일링)를 활용하면 GPU 사용률을 기반으로 Pod 자동 확장도 가능
4. CPU 노드풀과 GPU 노드풀의 병행 운영
용도
- CPU 노드풀: 전처리, API 서버 운영, 모니터링/로그 수집 용도
- GPU 노드풀: 학습/추론 워크로드 실행
오토스케일링
- Cluster Autoscaler: 노드풀 자원 부족 시 VM 자동 증감
- 가용 영역(Zone): 선택은 무료, 다만 존 간 네트워크 트래픽/스토리지 ZRS는 추가 비용 발생
고가용성
- GPU 노드풀은 최소 3개 영역에 배치 권장
- 노드 장애 → VMSS 자동 복구 기능으로 대체 가능
* AKS GPU 노드 풀끼리의 통신은 기본적으로 InfiniBand + RDMA로 구성됨.
5. 스토리지 선택 가이드
- Standard Blob: 대용량, 저비용, 장기 보관/분석 원본 저장
- Premium Blob: 빠른 응답, 작은 파일/트랜잭션 위주
- Azure Disk/Files: 일반 앱, 로그 저장, 단순 분석에 충분
- NetApp (ANF): NFS/SMB 지원, 고비용, HPC 환경 자주 사용
- Lustre: 초고성능 HPC 전용, AI/ML 트레이닝, 빅데이터에 적합
- 파일 시스템 단위로 생성 (용량 조정 불가 → 사이즈 조정할려면 새로운 FS 생성하고 rsync를 통해 데이터 이관 해야 됨)
- 비용은 처음 생성한 크기만큼 나감
- PVC로 선언 후 Pod에서 사용 가능
- 데이터는 여러 OST(Object Storage Target)에 분산(Striping)되어 병렬 성능 우수
대부분 병렬 처리 HPC 스토리지 솔루션으로 Lustre 사용
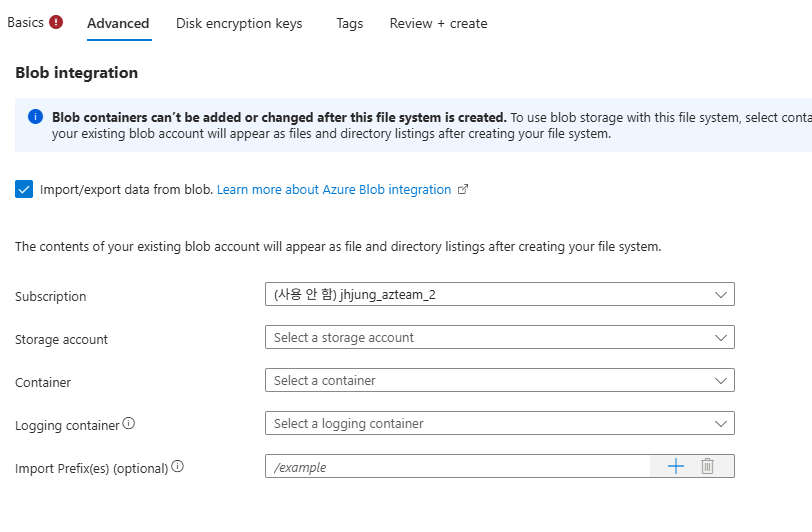
처음에 Lustre 만들 때 Blob 스토리지와도 Integration 가능
- 장기간 보관할 필요가 있는 학습 데이터 원본, 로그, 체크 포인트 등을 Lustre에 계속 두면 불필요한 비용 발생
- 자주 사용하지 않은 데이터는 Blob에 두고 Lustre는 자주 쓰는 핫 데이터로만 사용
* Lustre는 AKS에서 구성할 경우 Storageclass(파일 시스템명, 주소 명시), PVC(어떤 Storageclass를 사용하고 용량을 어떻게 설정할지)를 명시
* storageclass-lustre.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: lustre-sc
provisioner: azurelustre.csi.azure.com
parameters:
mgs: 10.1.0.8@tcp0
fsname: werwer #fs 이름
reclaimPolicy: Retain
volumeBindingMode: Immediate
* pvc-lustre.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: lustre-pvc
spec:
accessModes: [ "ReadWriteMany" ]
resources:
requests:
storage: 100Gi
storageClassName: lustre-sc
* pod-lustre.yaml
apiVersion: v1
kind: Pod
metadata:
name: lustre-test
spec:
containers:
- name: ubuntu
image: ubuntu
command: ["sleep","3600"]
volumeMounts:
- name: lustre
mountPath: /mnt/lustre
volumes:
- name: lustre
persistentVolumeClaim:
claimName: lustre-pvc
* 테스트
kubectl apply -f storageclass-lustre.yaml
kubectl apply -f pvc-lustre.yaml
kubectl apply -f pod-lustre.yaml
kubectl exec -it pod/lustre-test -- bash
ls -al /mnt/lustre6. AKS 업그레이드 고려 사항
Managed Kubernetes를 사용할 때의 이점
운영 단순화
- 컨트롤 플레인(API Server, etcd, Scheduler, Controller 등)을 Microsoft가 관리 → 사용자는 워커 노드와 애플리케이션에 집중 가능.
자동 업데이트/보안 패치 지원
- 쿠버네티스 버전 업그레이드, 노드 이미지 보안 패치 등을 자동화 가능.
장기 지원(LTS) 옵션
- AKS Premium SKU를 사용하면 쿠버네티스 버전 지원 기간을 12개월 → 24개월로 연장 가능.
- 업데이트 영향이 부담될 경우 일정 지연 가능.
업데이트 제어
- 자동 업그레이드 스케줄러를 통해 클러스터/노드풀 업데이트 시점을 원하는 시간대(예: 새벽 시간)로 지정 가능
업데이트 관련 고려사항
컨트롤 플레인 업그레이드
- Azure가 관리하는 영역.
- 고가용성(HA) 구조로 운영되기 때문에 업그레이드 중에도 API 서버 응답이 잠깐 지연되는 수준.
- 클러스터 전체 다운타임은 없음.
노드 풀 업그레이드
- 쿠버네티스 버전 업그레이드 또는 OS 이미지 교체 시, 롤링 방식으로 진행됨:
- 새 노드 VM 생성
- 기존 노드의 Pod을 새 노드로 이동 (drain → 재스케줄링)
- 기존 노드 제거
- 이 과정에서 **PodDisruptionBudget(PDB)**를 설정하면:
- 한 번에 모든 Pod이 내려가는 것을 방지
- 최소 가용 Pod 수를 보장 → 서비스 다운타임 최소화 가능
* PDB(PodDisruptionBudget) 기본 구조
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: myapp-pdb
spec:
minAvailable: 2 # 최소 2개는 항상 살아있어야 함
selector:
matchLabels:
app: myapp
'서버 > Azure' 카테고리의 다른 글
| [Azure] VPN Gateway를 통해 Private AKS 접근 (P2S) (0) | 2025.10.02 |
|---|---|
| [Azure] AKS Node Pool (Node)에 SSH로 안전하게 접속 (0) | 2025.09.30 |
| [Azure] Managed Lustre + Blob Integration (HPC Cache 권한) (0) | 2025.09.29 |
| [Azure] AKS ACR과 ArgoCD GitOps 배포 (feat 불변 태그 전략) (0) | 2025.09.05 |
| [Azure] SSL/TLS End-to-End (feat Service Mesh) (2) | 2025.08.21 |



