프로비전된 처리량 단위(PTU)와 관련된 비용 이해 - Microsoft Foundry
Microsoft Foundry에서 프로비전된 처리량 비용 및 청구에 대해 알아봅니다.
learn.microsoft.com
PTU는 “프로비전된 처리량 단위(Provisioned Throughput Unit)”라는 용어로, AOAI에서 모델 추론 처리 용량을 예약해 확보하는 단위입니다.
- 쉽게 말해, API 요청이 많이 들어오거나 Latency가 민감한 상황에서 throughput과 예측 가능한 비용 구조를 갖기 위해 미리 리소스(capacity)를 확보해두는 모델.
- PTU 하나가 얼마의 처리량(토큰 수, 분당 요청 등)을 의미하는지는 모델 종류, 프롬프트 크기, 응답 생성 크기, 동시 요청 수 등에 따라 달라짐.
- 즉 분당 토큰(TPM)을 얼마나 많이 처리 할 수 있는지에 대한 처리량 단위.
PTU를 사용하는 이유?
기본적으로 AOAI (Azure OpenAI Service) 에서는 Pay-As-You-Go(PAYG) 방식이 존재함.
즉 사용한 만큼 토큰 또는 호출 단위로 과금되는 방식임. (종량제)
Latest Updates to Azure OpenAI Service. - Node4
4th November 2024 Article The Node4 Team Latest Updates to Azure OpenAI Service Understanding the enhancements and updates. Azure OpenAI is a powerful clo ...
node4.co.uk
하지만 PAYG 방식은 다음과 같은 제약이 발생할 수 있음.
- 트래픽이 많거나 동시 요청이 많을 때 지연이 커질 수 있음.
- 공유 리소스 기반이다보니 처리량이 불안정할 수 있음.
- 사용량이 변동적이면 비용 예측이 어려울 수 있음.
반면 PTU 방식은 다음과 같음.
- 트래픽 패턴이 일정하고 예측 가능함. (분당 요청 수, 토큰 처리량 등)
- 실시간 또는 지연 시간에 민감한 요구 사항이 있는 경우
- PAYG 방식으로는 처리량이 불안정해지거나 과금이 예측 불가능할 때.
PTU 동작 방식
- 먼저 구독 단위로 각지역별 PTU 할당량이 존재함.
- 이 할당량 내에서 PTU를 배포에 할당할 수 있음.
- PTU를 할당한 뒤, 해당 용량을 사용하는 모델 배포를 만든다. 예를 들어 어떤 GPT-모델을 선택하고 “Provisioned Managed” 또는 지역/전역 배포 형태를 선택하는 방식.
- 배포가 활성화되면 그 PTU 용량은 사용 여부와 관계없이 확보돼 있으며, 사용량이 많아도 지연이 커지지 않음.
- 다만, 만약 요청이 확보된 PTU 용량을 초과하면 API가 HTTP 429(Too Many Requests) 상태를 반환하면서 요청 거절.
429를 보낼 때를 결정하는 법
- PTU 버킷 즉 처리 용량을 넘어버리면 Azure는 Leaky Bucket 알고리즘을 변형해서 처리함.
- 바로 429 반환하고 다시 재시도 하는 retry-after-ms 헤더도 포함.
- 용량이 100% 이하라면 prompt_tokens + max_tokens(사용자가 요청한 최대 생성 토큰 수) 를 기반으로 대략 얼마나 계산량을 먹을 것인지 추정해서 용량에서 먼저 차감해 둠.
- 실제가 더 컸다면 더 쓴 만큼 추가로 용량 차감하고, 실제가 더 적었다면 남은 만큼 돌려놓기.

PTU 배포 구조
구독 단위로 각 지역마다 할당되는 PTU
- PTU 할당량은 특정 Azure 구독 내에서 특정 지역에 배포할 수 있는 최대 PTU 수량을 정의. 이는 구독별, 지역별, 모델별로 관리.
- 예를 들어 '미국 동부' 지역에 GPT-4 모델에 대해서 100 PTU 할당량이 있다고 가정
- 100 PTU 할당량 내에서만 배포 가능하고 그 이상 배포할려면 MS에 할당량 요청
- 50 PTU로 배포한다고 했을 때 이 모델을 구동하기 위한 컴퓨팅 자원을 50 PTU 크기로 할당 요청
- 중요한 점은 할댱량은 최대 배포 가능한 한도
- 실제 용량(Capacity)은 Azure 데이터센터에 남아있는 물리적 자원
- 즉 50 PTU 만큼의 물리적 자원이 남아있지 않다면 배포가 이루어지지 않음.
PTU 예약 할인 구조
PTU 할인을 샀으면, 실제로 쓴 PTU가 그 할인 범위 안에 있어야 할인이 적용되고, 할인을 샀더라도 다 쓰지 않으면 남은 할인은 사라짐.
- 예약(할인)은 고객이 미리 구매한 PTU 수량과 실제로 배포하여 사용한 PTU 수량을 시간 단위로 비교하여 적용.
- 예시 : 100 PTU 할인을 샀고, 해당 시간에 80 PTU를 사용했다면, 80 PTU는 할인 가격으로 청구.
- 초과 분은 종량제 청구함
- 만약 사용자가 예약한 PTU보다 많다면 (예를 들어 120 PTU) 예약된 100 PTU에 대해서는 할인 가격이 적용되지만, 초과된 20 PTU에 대해서는 할인 없이 시간당 종량제 가격으로 청구.
PTU는 시간 단위로 계산되지만, 정확히 1시간을 채우지 못해도 손해 보지 않도록 분 단위로 비례하여 계산.
- 비례 조정 : 만약 1시간(60)분 동안 100 PTU를 배포했는데, 실제 사용 시간이 15분이었다면, 15분은 1시간의 1/4
- 즉 해당 시간에는 25 PTU를 사용한 것으로 간주하여 청구 및 예약 할인이 적용됨.
할인을 적용받으려면 할인 구매 범위와 실제 PTU 배포 위치가 일치해야 한다.
- 범위 지정 : 예약을 구매할 때, 이 할인을 단일 구독에만 적용할지, 아니면 여러 구독에 걸쳐 적용할지 범위를 지정
- 일치 필수 : 단일 구독에 지정된 예약은 반드시 해당 구독 내의 PTU 배포에만 적용됨. 다른 구독에 있는 PTU 배포는 그 구독에 별도 예약이 없다면 할이 없이 종량제로 청구.
사용하지 않은 예약은 소멸 (이월 불가)
- PTU 예약은 24시간/주 7일(연중무휴) 사용하는 것을 가정하고 가격이 책정
- 만약 예약한 PTU(할인)보다 실제로 사용한 PTU가 적은 경우, 사용하지 않고 남은 초과 예약 PTU는 손실 됨.
- 예시 : 100 PTU를 예약했는데, 해당 시간에 50 PTU만 사용했다면, 남은 50 PTU의 예약 혜택은 사라지며, 다음 시간이나 다른 기간으로 이월되지 않음.
PTU 계산을 위한 필수 정보
- 모델별 1 PTU당 TPM 값
- 예상되는 최대 동시 요청 : 테스트 기간 중 가장 바쁜 순간에 분당 몇 건의 API 요청 수가 일어나는지.
- 평균 요청(입출력)당 토큰 수 : 평균 질문 길이와 답변 길이를 합쳐 요청당 평균 몇 토큰이 예상되는지.
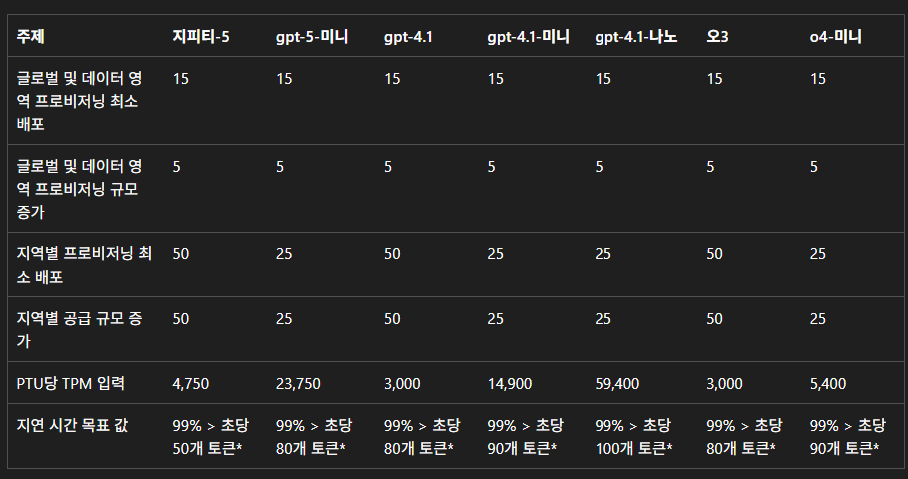
예)
1 PTU당 TPM : 15000 TPM (모델마다 PTU 당 TPM 다름)
최대 분당 요청 수 : 피크 타임에 초당 약 13-14명 즉 분당 800요청
평균 입력 토큰 : 2000 토큰
평균 출력 토큰 : 500 토큰
요청 당 총 토큰 산정
요청당 총 토큰 = 평균 입력 토큰 + 평균 출력 토큰
2,000 토큰 + 500 토큰 = 2,500 토큰/요청
최대 요구 TPM 산정
800 요청/분 x 2500 토큰/요청 = 2,000,000 TPM
필요 PTU 수량 계산
필요 PTU = 최대 요구 TPM / 1 PTU당 TPM
2,000,000 TPM / 15000 TPM/PTU = 133.33 PTU
모델별 최대 입출력 토큰
Azure에서 직접 판매하는 Foundry Models - Microsoft Foundry
Azure에서 직접 판매하는 Microsoft Foundry 모델, 해당 기능, 배포 유형 및 AI 애플리케이션의 지역 가용성에 대해 알아봅니다.
learn.microsoft.com
'서버 > Azure' 카테고리의 다른 글
| [Azure] Application Gateway for Containers (0) | 2025.11.28 |
|---|---|
| [Azure] Frontdoor + Private Link + AppGW (0) | 2025.11.27 |
| [Azure] ACL(Azure Confidential Ledgers) 개요 및 구축 (0) | 2025.10.22 |
| [Azure] VPN Gateway를 통해 Private AKS 접근 (P2S) (0) | 2025.10.02 |
| [Azure] AKS Node Pool (Node)에 SSH로 안전하게 접속 (0) | 2025.09.30 |



